模式匹配
暴力算法:最好 ,最坏
KMP
建立一张表,在比对失败后不再从头开始比对,而是从模式串中某一字符开始比对,且使得模式串的前缀已经匹配。
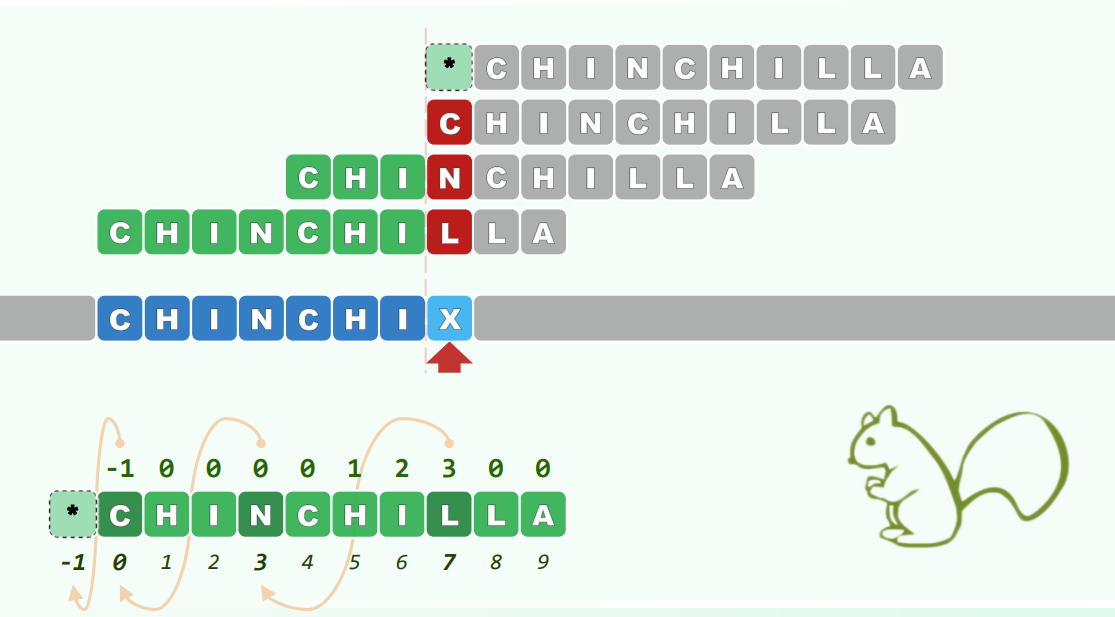
构造 next 表
显然 ,通过递推构造剩余的 next 表:
- 取
- 若 ,有
- 否则令 ,继续迭代
均摊分析
Aggregate
令 ,
 若匹配, 正好加一
若不匹配,查跳转表, 必然减少, 至少加一
因此 单调递增,是操作次数的上界。
终态 ,因此时间复杂度为
若匹配, 正好加一
若不匹配,查跳转表, 必然减少, 至少加一
因此 单调递增,是操作次数的上界。
终态 ,因此时间复杂度为
Accounting
若匹配,则记账至当前元素,每个元素必然只出现一次这种记账 若不匹配,则记账至当前匹配的首元素,由于匹配的首元素必然递增,每个元素必然只出现一次这种记账。 因此时间复杂度为
改进
若出现失配,在跳转后应该希望当前元素和跳转后位于当前位置的元素不同,否则又会导致失配 只需在构造 next 表时保证
- 取
- 若 ,取 ,继续迭代
- 否则若 ,令
- 否则令 ,由数学归纳法,此时的 必然可以保证
总结
字符集越小,优势越明显,否则与暴力性能相近 最坏和平均时间复杂度均为
BM
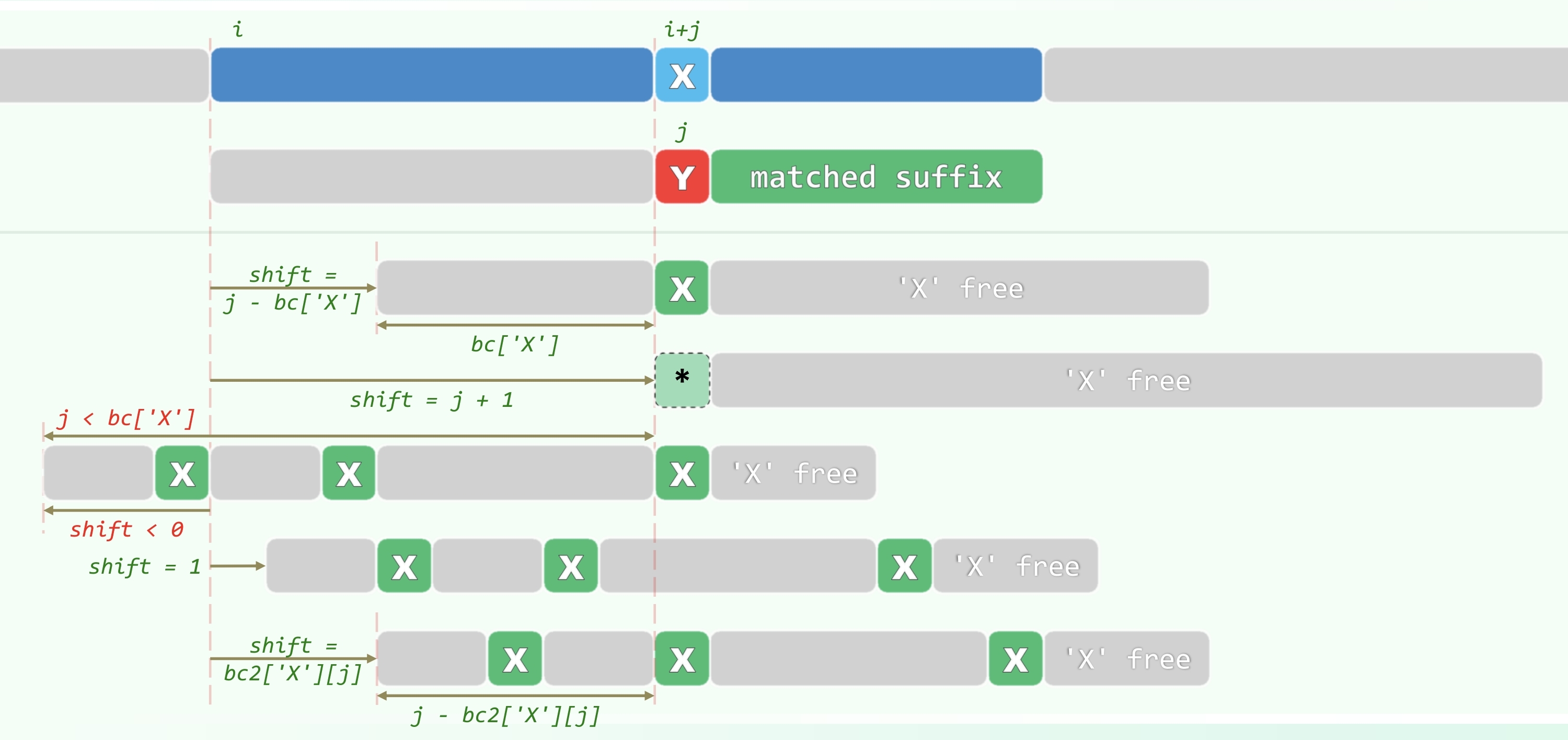
BC 策略
每次匹配时从右向左遍历 P,遇到不匹配的字符,借助 bc 表快速右移到第一个使得当前字符匹配的位置,再重新从右向左匹配。
bc 表的构造
表长为 ,每个元素代表 中对应字符最靠后的位置 使用画家算法,初始化为 -1,从前向后遍历字符串并更新表
性能
- 最好情况:若 中不包含失配的字符,则可以直接跳过整个串,
- 最坏情况:匹配到迭代中的最后一个字符才失配,且匹配串中包含了全部字符,则只有每次匹配全串后才能右移一步,退化为暴力算法,
- 字符集越小,越容易出现最坏情况 仅仅利用了失配的信息,能否利用上已匹配后缀的信息?
GS 策略
匹配时从后向前遍历 ,遇到第一次失配时,可以知道此时 的后缀是匹配的,跳转到最靠后的与这段后缀相同,且当前待匹配字符不同的 的中缀。若不存在这样的中缀,则跳转到与这段后缀匹配的最长前缀(可能为空,此时等同于跳转到开头)。
gs 表中保存的是右移字符数
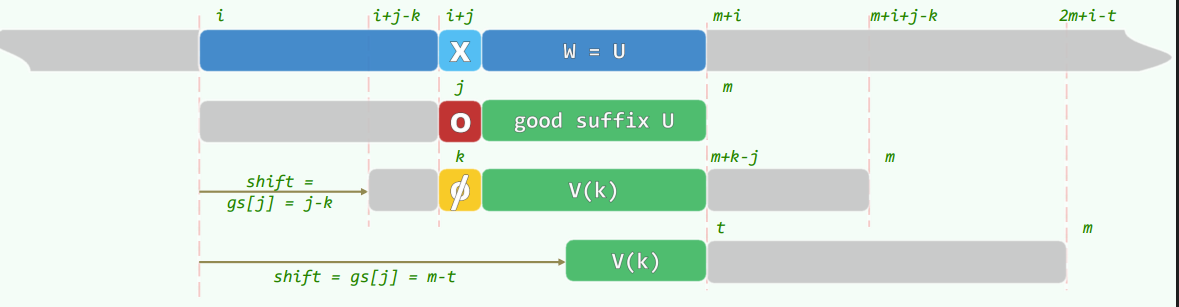 如何构造 gs 表?
如何构造 gs 表?
ss 表
定义 ss 表,对于每一元素,ss 的值为以该元素为末尾的最长的与 的后缀匹配的中缀的长度。
ss 表的构造
问题转化为如何构造 ss 表。暴力算法时间复杂度为
从后向前扫描,维护一个匹配区间 ,满足该区间与后缀可以匹配。
首先 ss[m-1] = m,接着从倒数第二个字符开始从右向左扫描。
对于当前元素 ,总有
- 若 ,此时 的局部和 相同(匹配的后缀内)且 ,可以直接套用之前的计算结果,
- 否则更新 ,从 开始继续逐一匹配,更新
- 对于 的情况,当且仅当 时进入该分支,此时保证了从 到 可以与后缀匹配。因此可以直接将 更新为 并从 开始进行匹配。
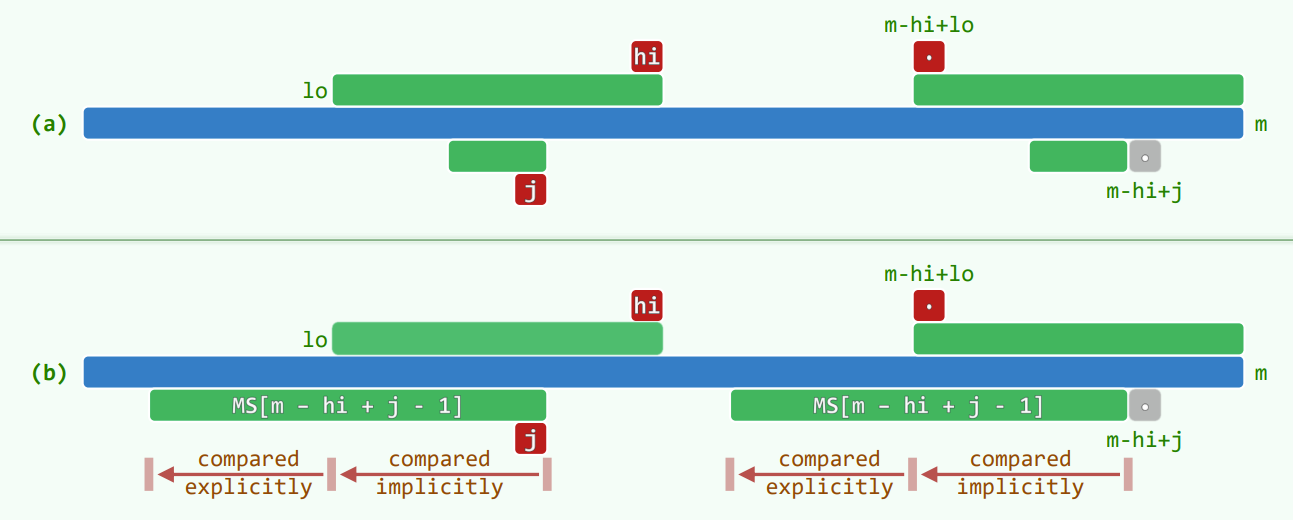
- 对于 的情况,当且仅当 时进入该分支,此时保证了从 到 可以与后缀匹配。因此可以直接将 更新为 并从 开始进行匹配。
由 ss 表构造 gs 表
可以由 ss 表在 内构造出 gs 表:
- 若 ,即整个前缀可以与后缀匹配,匹配的后缀的第一个元素的秩为 ,则对于任意 , 是 的一个候选
- 若 ,匹配的后缀的第一个元素的秩为 ,中缀的第一个元素的秩为 ,二者间隔 ,因此此时 是 的一个候选
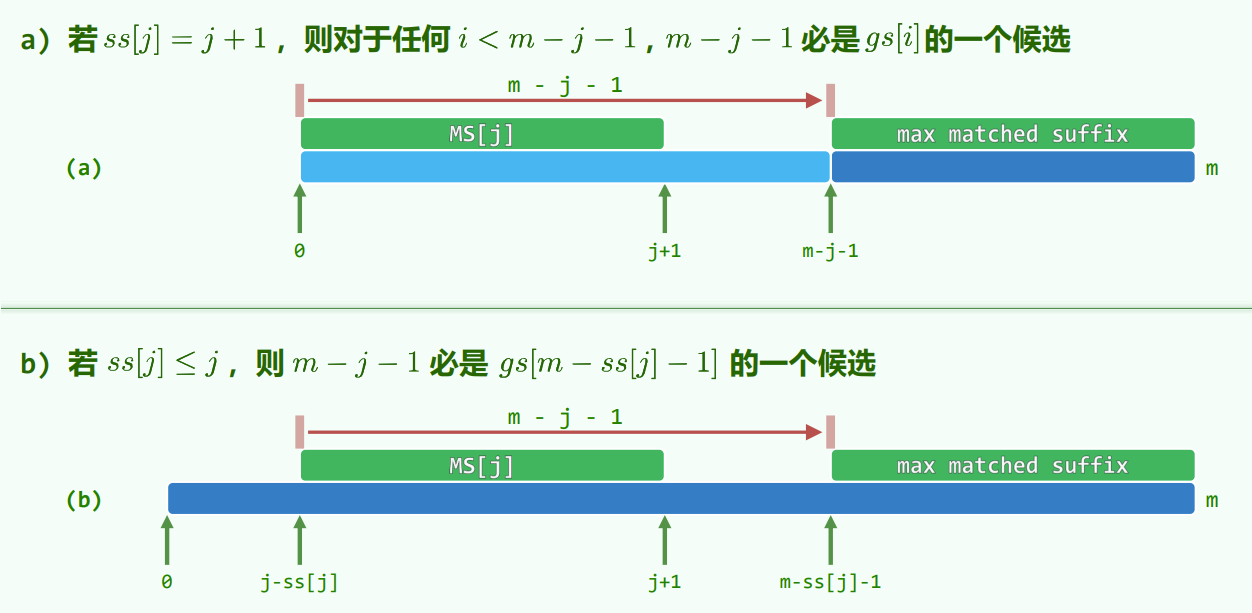 从后向前做一次遍历,检查所有 的情况,并将 赋值给上次赋值结束位置到 的元素(因为前一次的赋值更小)。
从后向前做一次遍历,检查所有 的情况,并将 赋值给上次赋值结束位置到 的元素(因为前一次的赋值更小)。
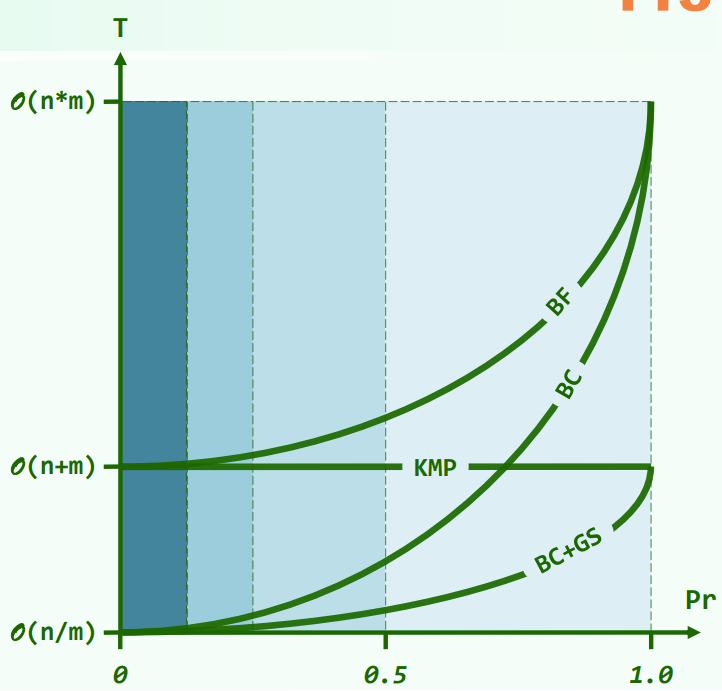
KMP vs BM
Karp-Rabin 算法
将串视为一个 进制数,通过散列映射到一个较小的空间中即可得到一个串的“指纹”。 时间内即可从上一指纹得到下一指纹。
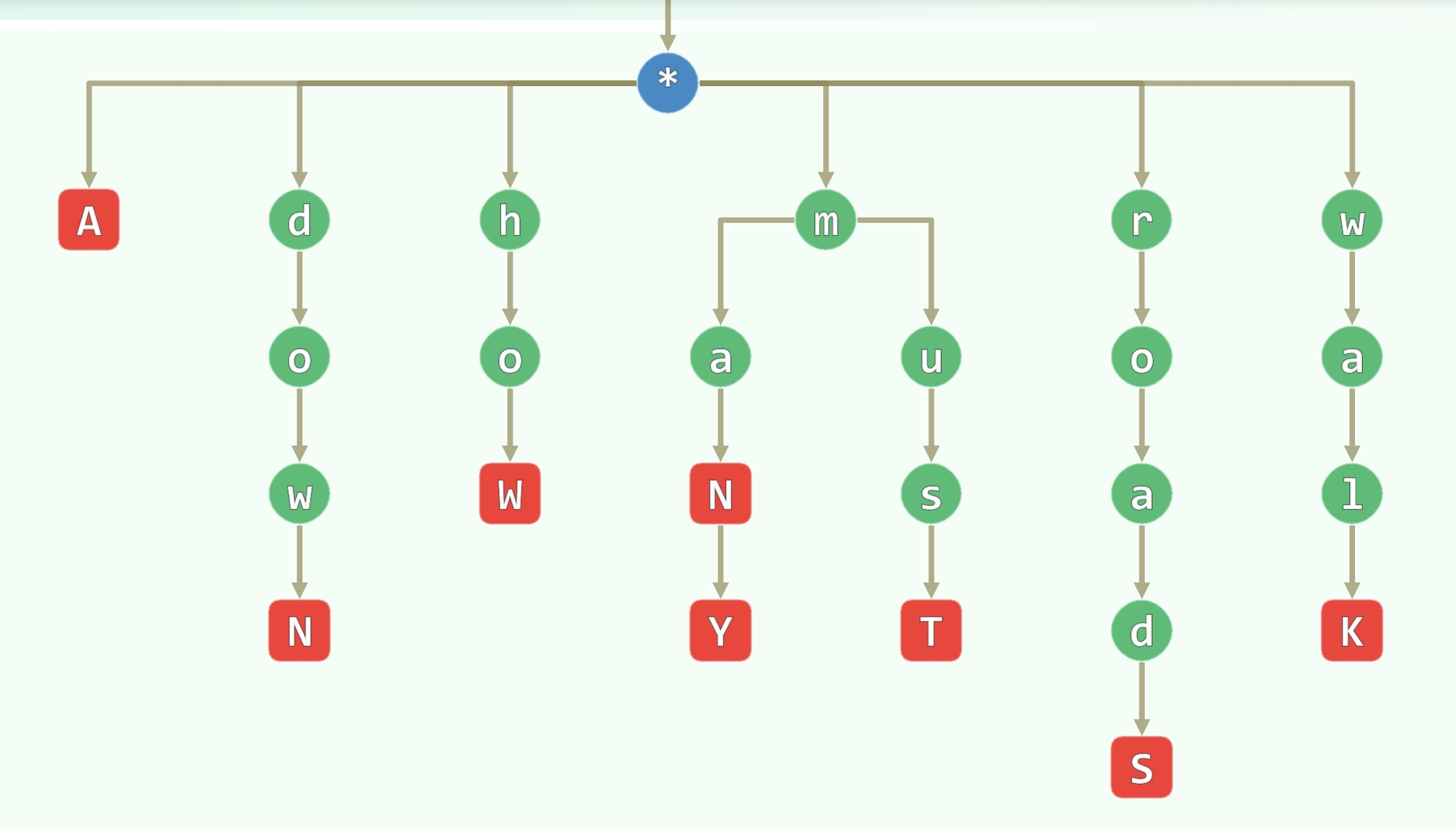
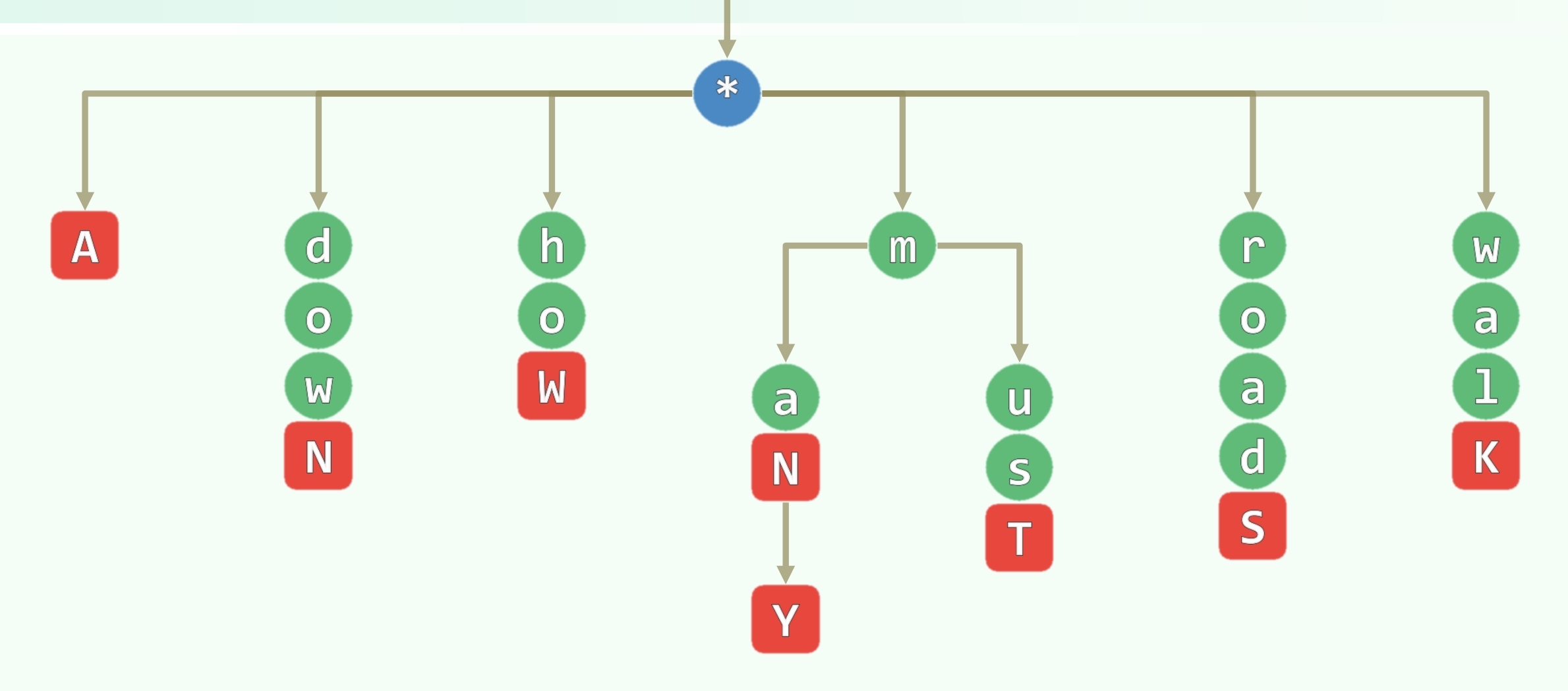
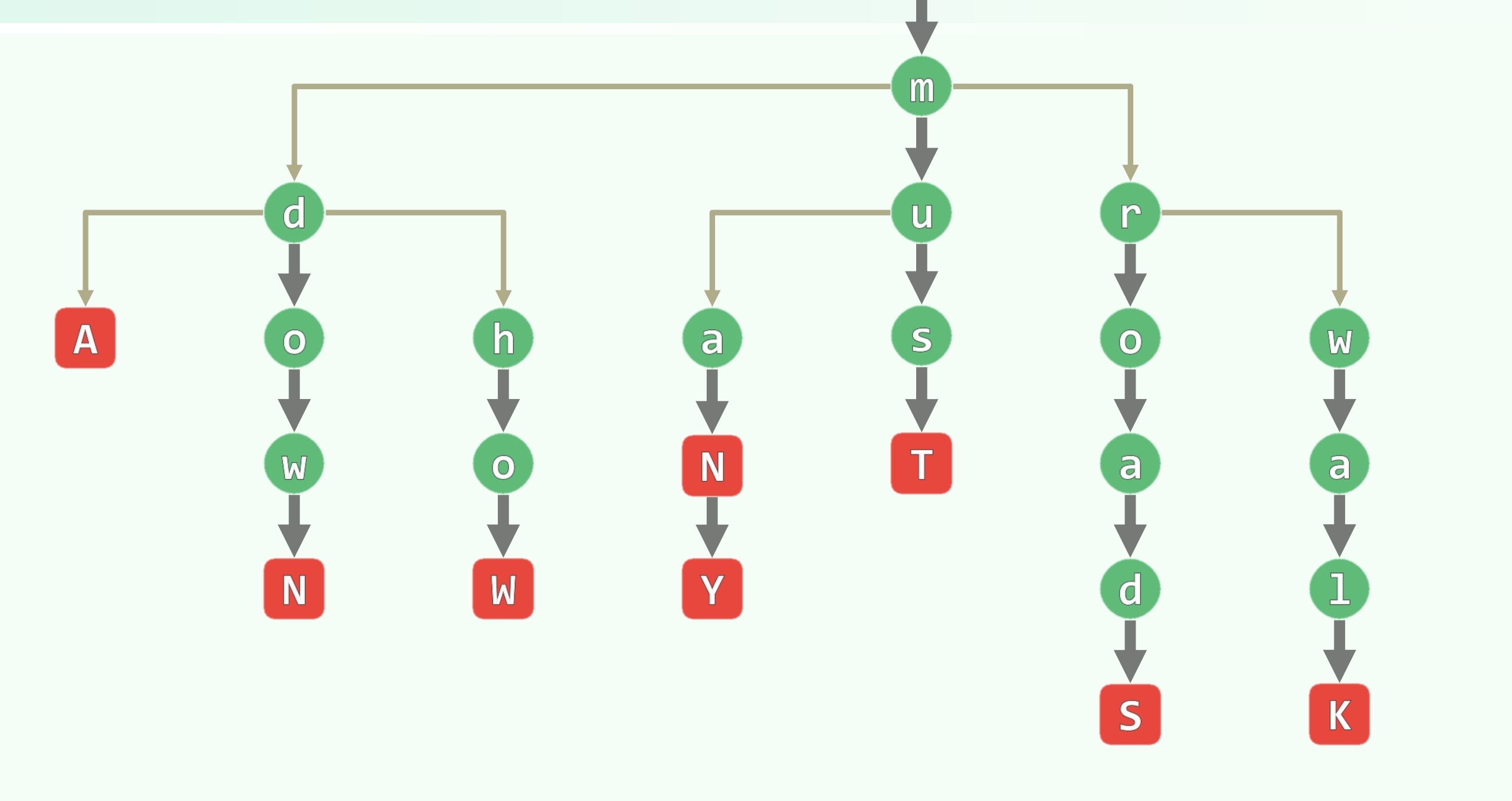
键树