快速排序
依据轴点做划分,使得
前缀和后缀各自递归即可。
- Insight: 相距更远的逆序对更优先被消除
一个序列有序当且仅当所有元素均为轴点。
划分 LUG
任取一个元素作为轴点,从两端交替向内移动 和 ,将小于/大于轴点的元素归入 L/G,最后将轴点归位。

- 线性时间
- 就地
- 不稳定
空间复杂度
取决于递归深度
- 最好:
- 最坏:
优化:迭代化+贪心,缺一不可 思想:小区间优先被处理
归纳假设:对长度 的序列,该算法所需空间不超过 对于长度为 的序列,算法执行过程分为三个阶段:
- 第一次划分后,
- 对小区间排序的过程中,
- 对大区间排序的过程中,此时小区间已经排序完成, 优化后可以保证空间复杂度为
为什么要求迭代化? 如果不迭代化,进行子任务时父任务的栈帧不会被释放,则最坏情况仍会达到
时间复杂度
- 最好:每次划分接近平均
- 最坏:每次划分不均衡
采用随机选取、三者取中的策略来降低最坏情况的概率。
递归深度
- 好轴点:落在居中的长度为 的区间内
- 坏轴点:落在两侧的长度共 的区间内
任何一条递归路径上,好轴点不会超过 个
由于好轴点个数和坏轴点个数之比的期望为
因此抵达 层时,期望已经出现了 个好轴点,因此期望在此之前结束递归。
- 任何一条递归路径的长度只有极小概率超过
比较次数
递推分析:
后向分析: 对于排序后的序列 ,考虑 和 进行过比较的概率 :
- 若 ,则 早于或晚于 和 被转化为 pivot 与二者是否被比较没有关系。
- 若 ,则 和 不会被比较。
因此 和 进行过比较当且仅当在 中, 或 最先被转化为 pivot,因此 ,期望总比较次数为
对比
 LGU 版实现的期望交换次数是期望比较次数的
LGU 版实现的期望交换次数是期望比较次数的
DUP
若有大量相同元素(甚至全部元素相同),则递归深度退化为 ,复杂度会退化为 在交替迭代 和 时,将判断当前元素是否小于等于/大于等于 pivot 改为判断当前元素是否小于/大于 pivot
- 一般情况下复杂度并未提高
遇到连续的相等元素时, 和 会交替移动,最终切分点接近 ,避免了递归深度的退化
- 交换次数有所增加,且更不稳定
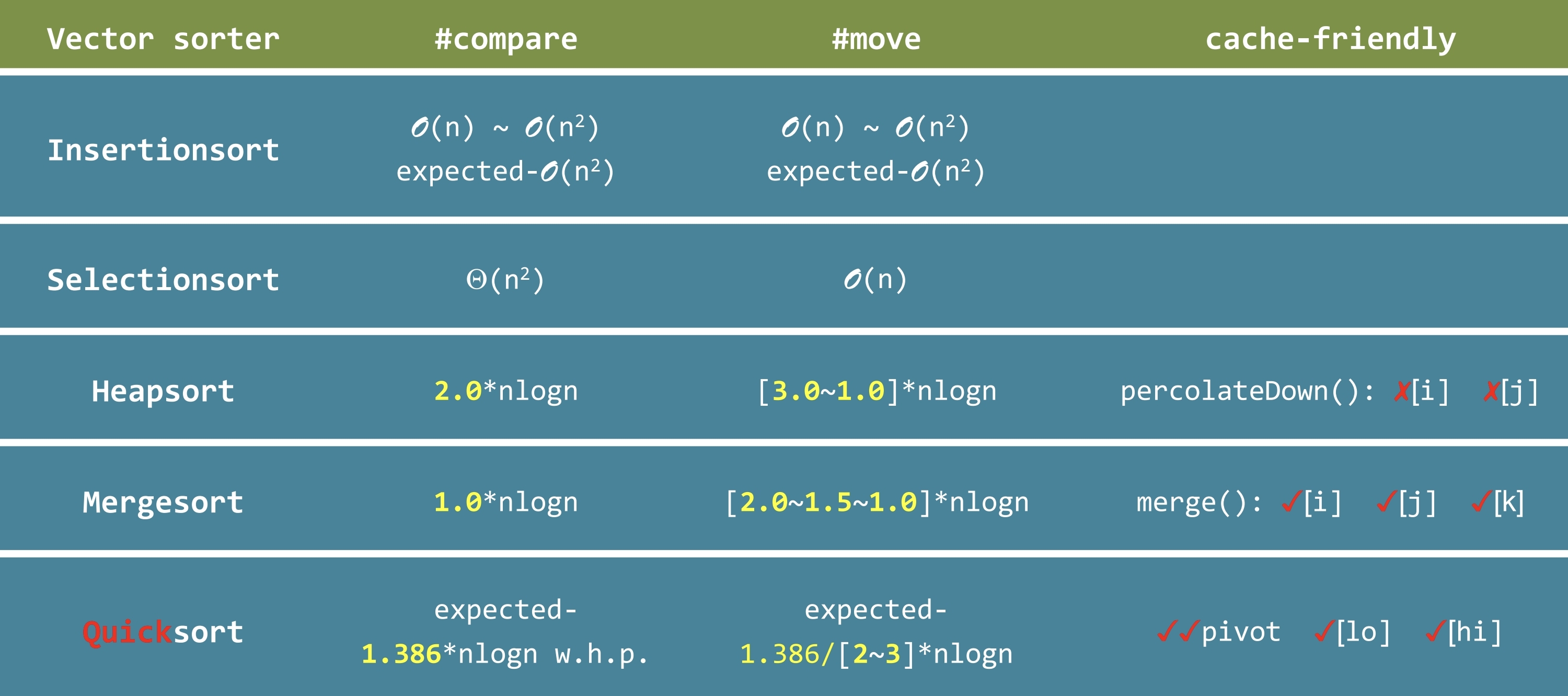
LGU
将数据划分方式从 LUG 改为 LGU
- 若当前元素小于 pivot,交换当前元素和
mi+1(G 的第一个元素) - 若当前元素大于等于 pivot,直接
k++ - 最后将 pivot 和
mi交换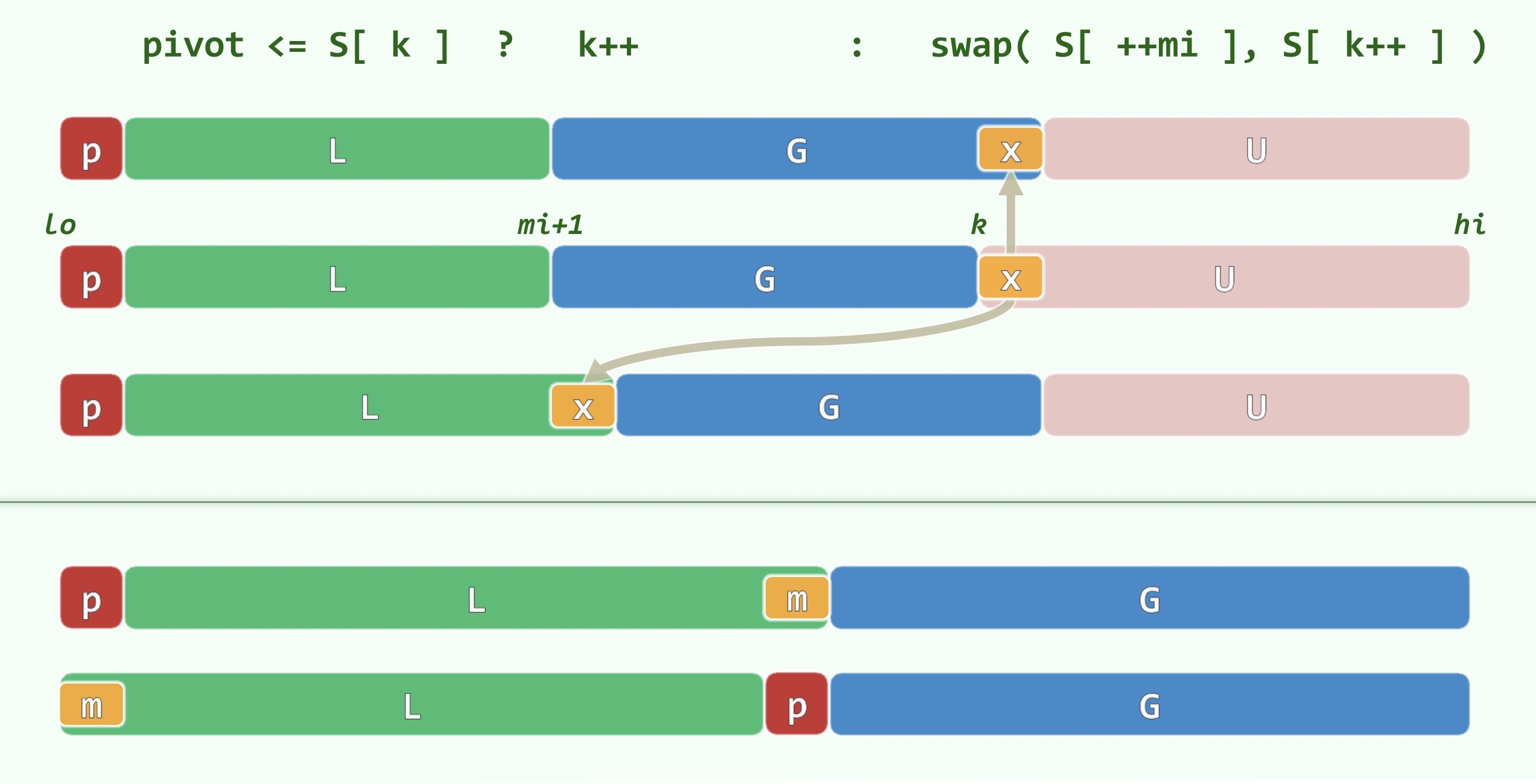 缺点:
缺点: - 交换次数多,每遇到一个 L 中的数就需要交换一次,期望上交换次数是比较次数的
- 不稳定
选取第 k 大
QuickSelect
反复做 QuickPartition,若猜大了则删除后缀,若猜小了则删除前缀
期望性能: 可以验证
LinearSelect
linearSelect(A, n, k):从 个数中找到第 小的数
为一个较小的值 0. 若 ,直接进行排序并返回答案,视为
- 否则,将序列切分为 个子序列
- 对每个子序列进行排列
- 每个子序列得到各自的中位数
- 将这些中位数作为一个新的序列,递归调用
linearSelect,找到中位数的中位数 - 将 作为 pivot,将 划分为 L/E/G 三部分
- 若 ,第 小在 中,返回
linearSelect(A, |L|, k);若 ,说明 就是第 小;否则返回linearSelect(A+|L|+|E|, |G|, k-|L|-|E|)
复杂度
- 对每个子序列进行排序:
- 收集所有子序列中位数:
- 递归找到中位数的中位数:
- 一次扫描,分类 L/E/G 并计数:
- 递归调用:
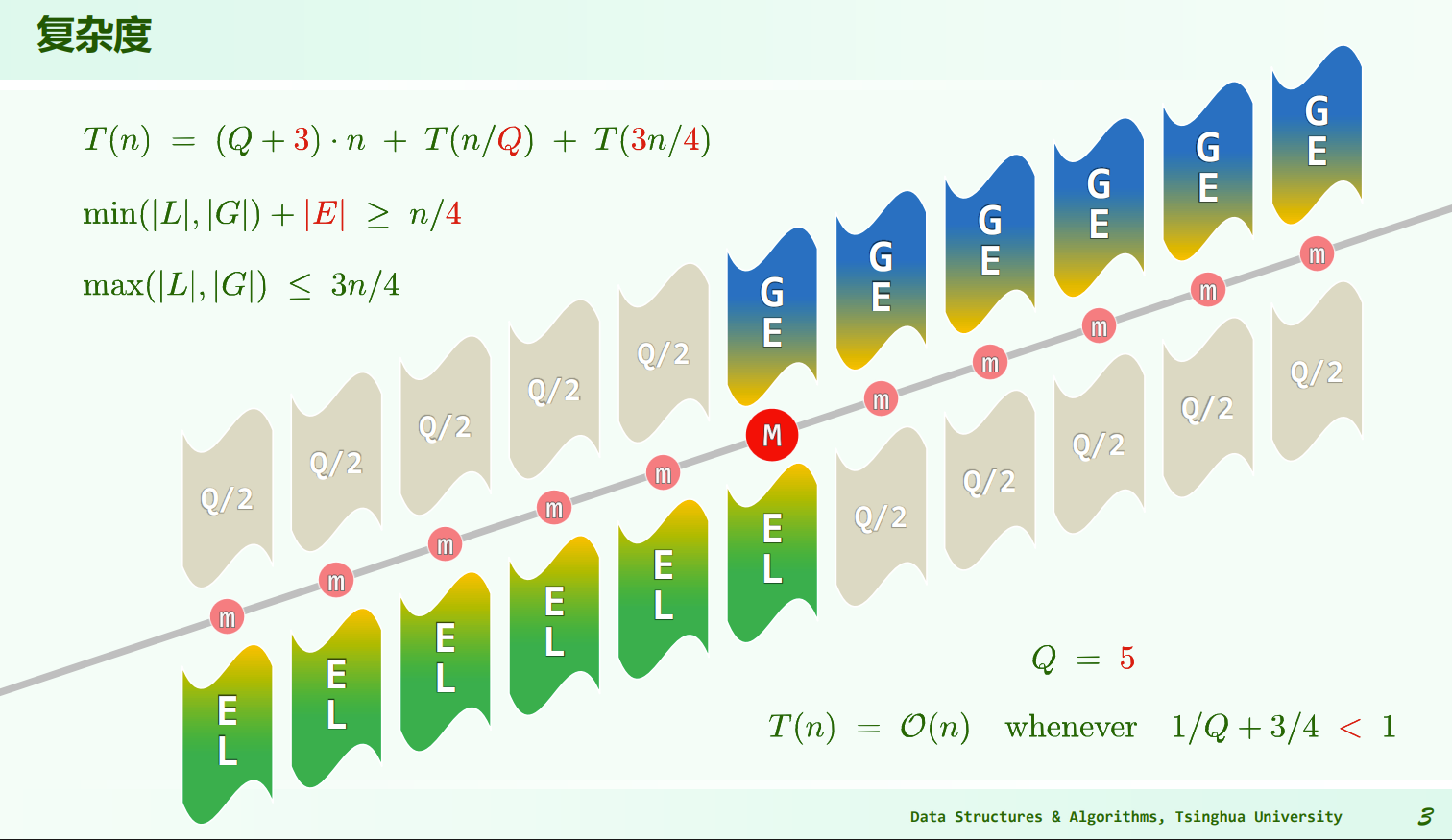 选取方式可以保证 :由图,绿/蓝+黄必然覆盖了 1/4 的数
选取方式可以保证 :由图,绿/蓝+黄必然覆盖了 1/4 的数
则
因此有递推式
只需保证 即可保证 ,取 即可
希尔排序
将整个序列视作一个矩阵,逐列进行排序,然后减少列数,重复直至列数为 1,此时再做一次排序即可。
Shell 序列
最坏情况下需 时间
 最后的全排序仍需 时间
最后的全排序仍需 时间
邮票问题
任给两个数 ,它们的线性组合能否表示另一个数 ?
当 互质时,它们的线性组合不能表示的最大自然数为
h-sorting & h-ordered
称一个序列为 h-ordered 当且仅当
Theorem
对于任意正整数, A g-ordered sequence remains g-ordered after being h-sorted.
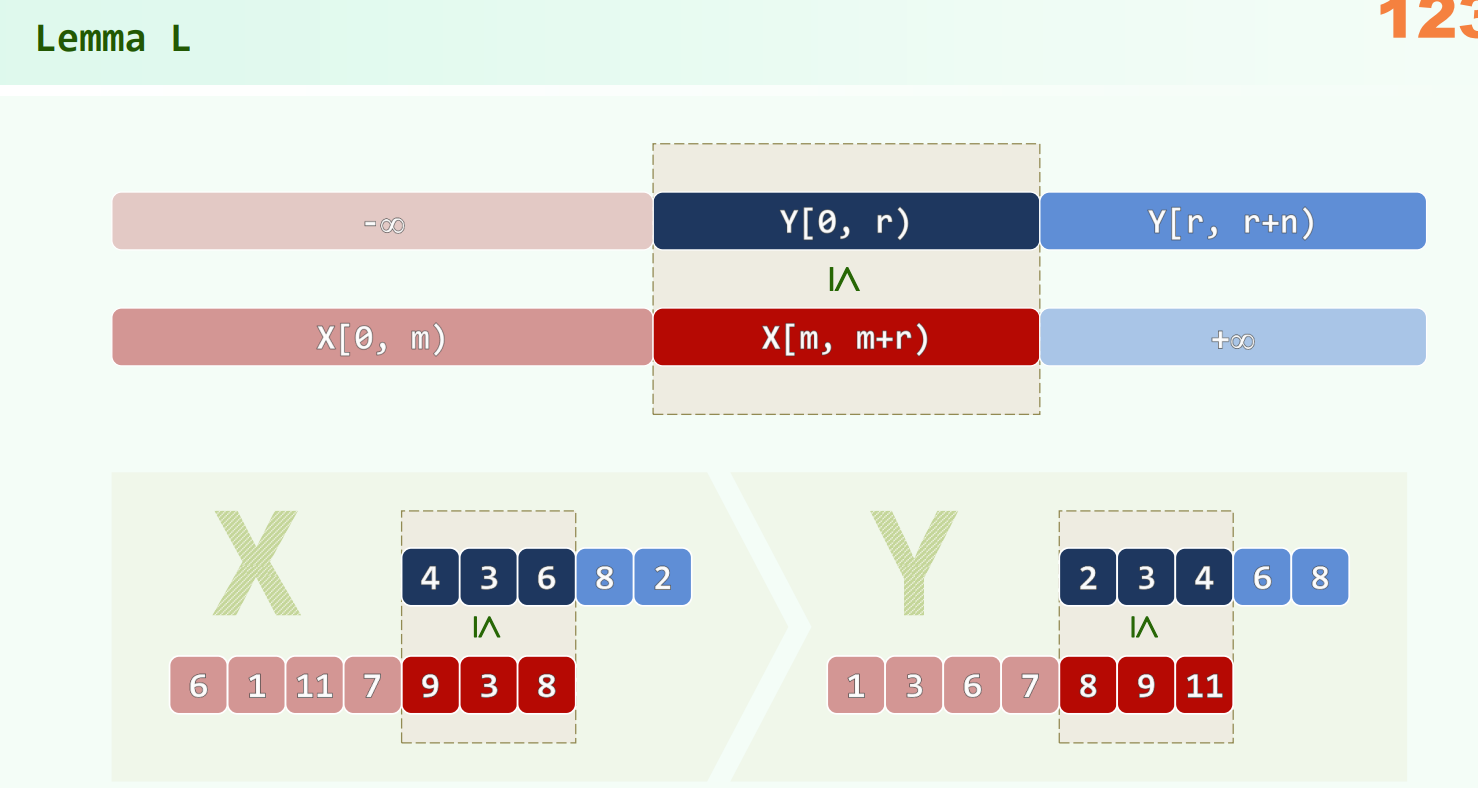
Theorem
一个同时为 g-ordered 和 h-ordered 的序列必然是 (mg+nh)-ordered 的
如果 互质,则对于任意的元素,只有前面的 个元素中可能出现逆序对,它和再之前的元素间必然有序。
PS 序列
若 互质,且均为 的,则可以在 时间内完成 d-sorting
相邻两个元素互质
需要进行 次外层循环
总时间复杂度为
Pratt 序列
时间复杂度为
需要过多次循环,对于接近有序的序列效率较低
Sedgewick 序列
最坏时间复杂度
平均时间复杂度