有序向量
Dedup 去重
- 勤奋的低效算法:从每个区段中删除第一个之后的所有元素。
- 最坏情况:全部元素相同,需要删除 次,复杂度为
- 懒惰的高效算法:仅保留各区段第一个元素,双指针法。
- 每一步为 ,总复杂度为
二分查找
默认查找区间为
A 版本
每次迭代比较 和待查找元素 :
- :位于前缀中
- :位于后缀中
- :命中
取 为中位数,则每次迭代或规模减半,或命中,复杂度为
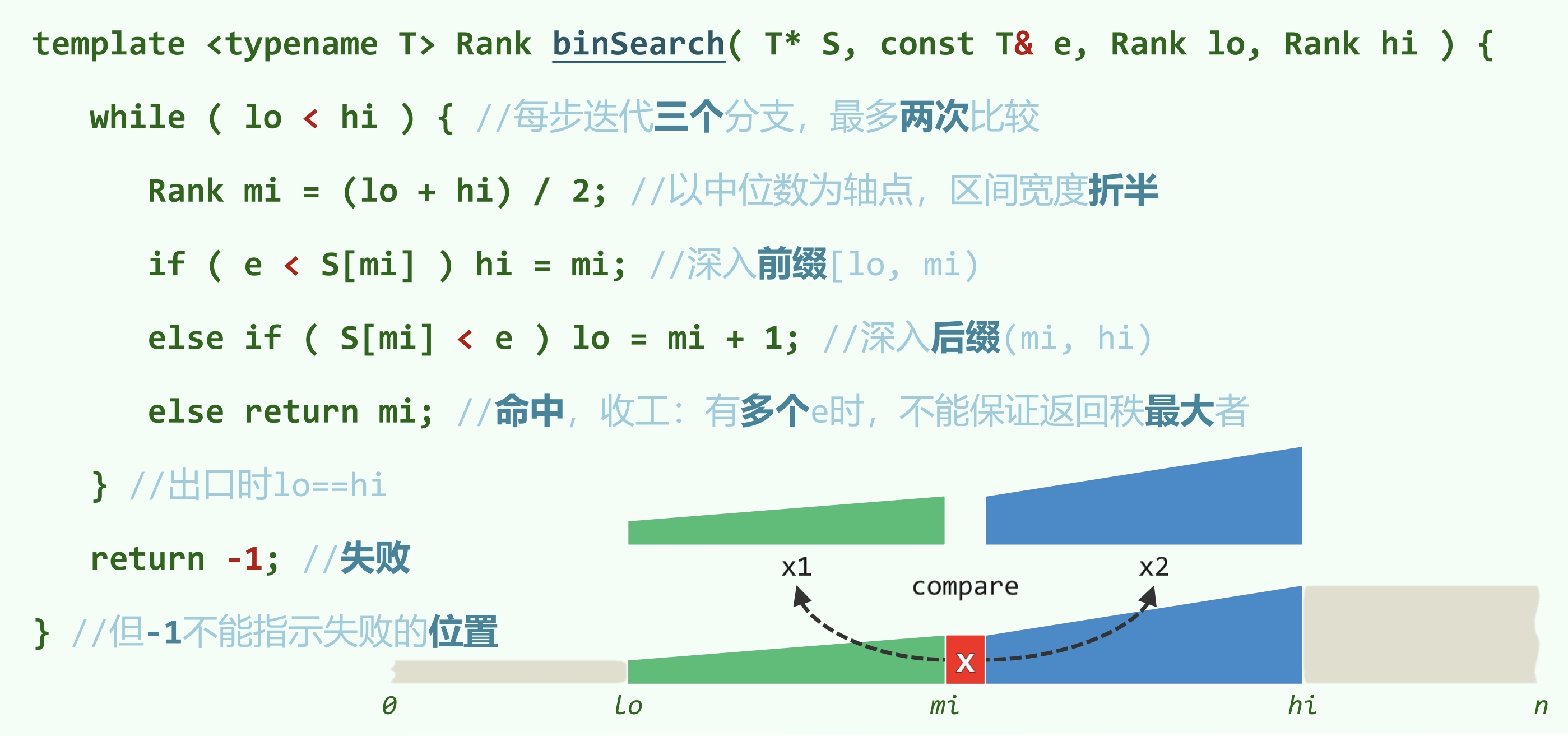
- 若失败时返回值改为
lo- 若成功,不能保证返回位置在多个相同结果中的相对位置
- 若失败,返回最小的大于查询值的位置(可能为 -1 或 hi) 常数较大,为 规模为 ,平均成功查找次数为 ,平均失败查找次数为 ,则有
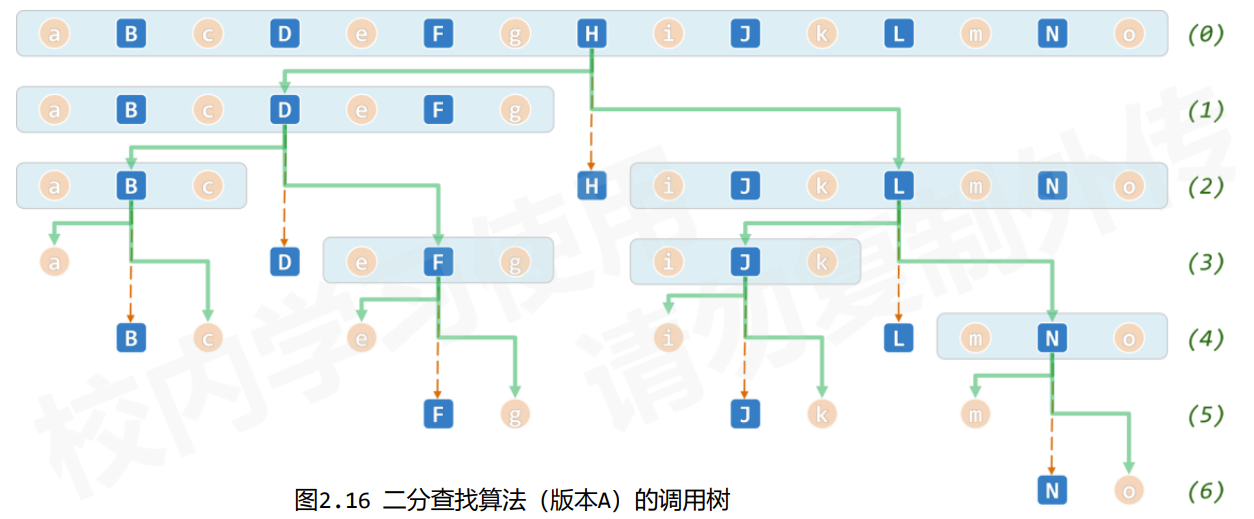
B 版本
改进方向:正好命中的概率很小,可以只在 时判断是否命中。
每次迭代只做一次比较,只有两个分支。
相比 A 版本,最好情况变坏,最坏情况变好,整体性能有所提升。
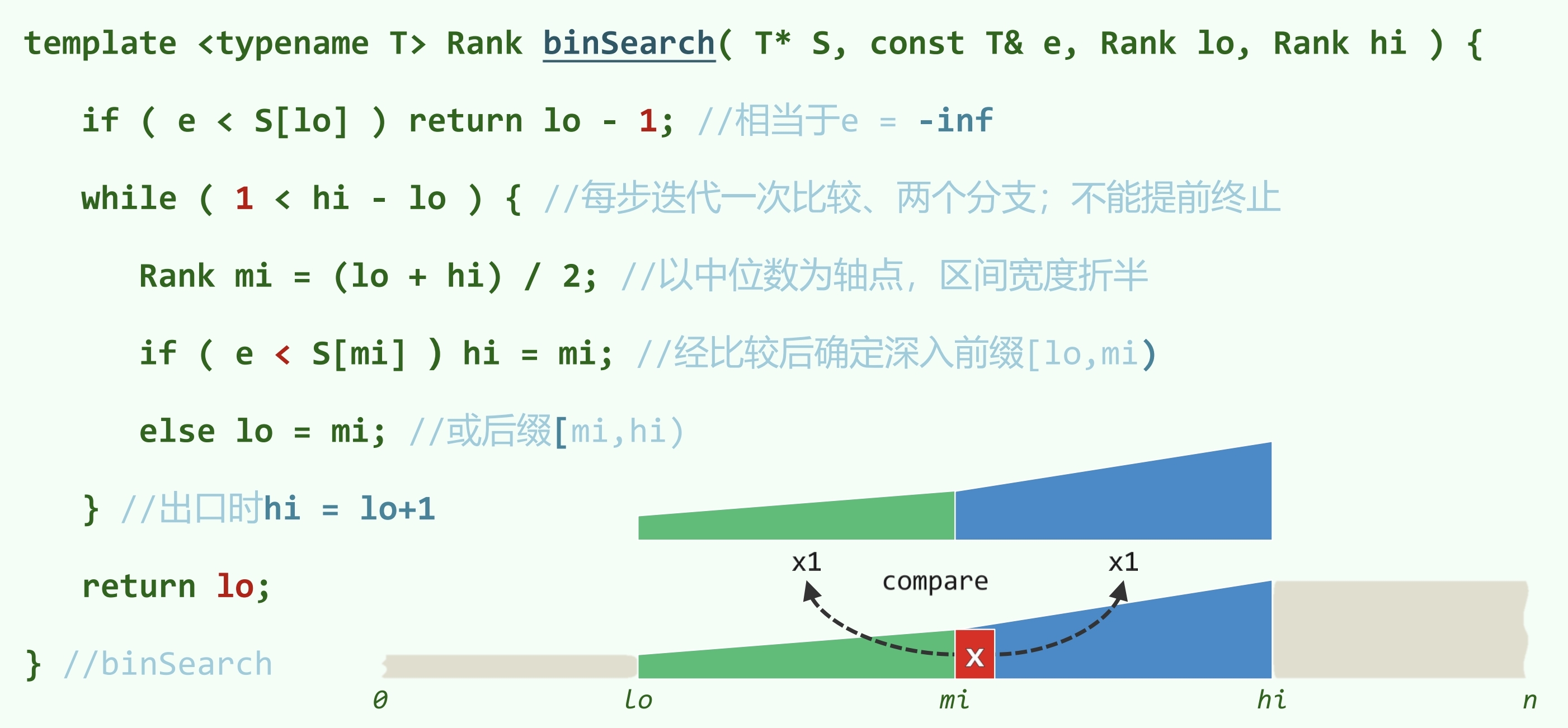 此外,B 版本总是返回不大于 e 的最大者,便于维护插入操作
此外,B 版本总是返回不大于 e 的最大者,便于维护插入操作 V.insert(V.search(e)+1, e)
C 版本

- Loop Invariant:
- 算法终止时,, 为不大于 的最大值, 为大于 的最小值。
- 常系数为
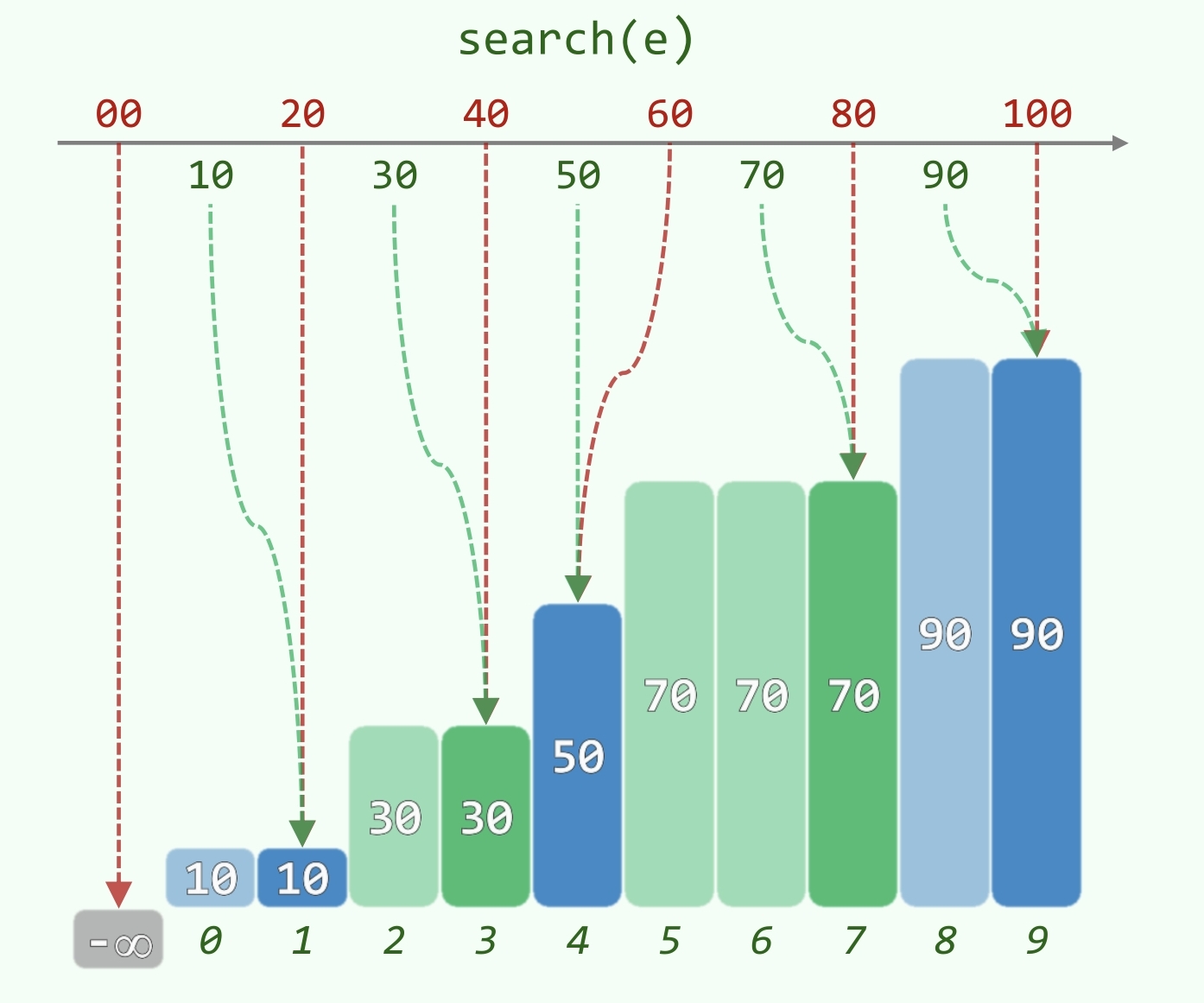
插值查找
- 越长的序列,元素的分布越有规律
- 对于独立同分布且服从均匀分布的序列, 内的元素的秩与数值近似呈线性关系
- 引理:每次猜测将问题规模从 减少到
- 时间复杂度:
- 最坏情况:
对比
- 二分查找:字长意义下顺序查找
- 插值查找:子长意义下折半查找
算法接力
首先通过插值查找缩小查找范围,再改为二分查找,最后改用顺序查找。